| Top Page | プログラミング | Perl 目次 | prev | next | 索引 |
前のページでは,DOS窓でプログラムを起動するときに指定した 既存ファイルを読み込む方法を説明しました. 一行ずつ読み込んだ文字列をsplit して文字列中の個々のデータに分割する方法も 解説しました.
このページでは,ここまでに出てきた事項をつかって,表計算ソフトで やろうとすると延々とマウスで手作業しないといけないような作業が プログラムを書くことで自動化できる例を紹介します.
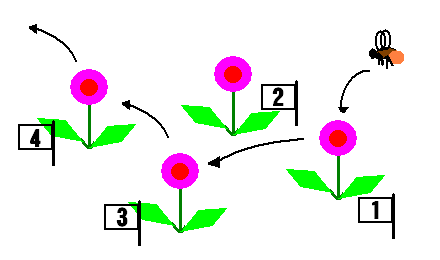
何個体もハナマルギク(仮名)が生育しているところで, ハナマルバチ(仮名)が花を訪れる様子を撮影したビデオを 再生して取ったデータがあるとします.
ハナマルギクの個体には全部個体の標識番号をつけてあります. データファイルには,ハチが何番の個体をいつ訪れたかが記録されています.
time plantID 0 1 12 3 20 4 28 0 0 3 10 2 16 1 21 2 24 0 .....
よそからやってきたハチがどれかのハナマルギクに降りたときが時刻ゼロです. キクの個体の標識番号(plantID)が 0 になっているのは,その時刻にハチが よそに飛び去ったことを表します. 一個体のハチの一連のデータのおわりには空白行が入れてあります. 上の例は2個体のハチのデータだけですが,実際には 254 個体分の データがあります(ということにしましょう).
このデータから,一個体のハチがこの場所にどれだけの時間とどまっていたか, そのあいだに何個体のキクを訪れたかを求めたいとします. 表計算ソフト上でやろうとすると,一度に処理するのはむずかしそう. 人間が目でみながら,ハチ一個体分づつについて見ていくことになりそうです. 254 個体分はけっこうたいへん. でも,こんな単純作業はコンピュータに片づけて欲しいものです. コンピュータに作業を言いつけるために, Perl のプログラムを書いてみましょう.
# bee_visit.pl ハチの訪花行動データの解析プログラム
$line = <>; # データファイルの最初の行 ("time plantID")を読む(だけ).
$count_plant = 0; # ハチの訪花数のカウンタを用意.
print "stay(sec)\tvisits\n"; # 分かりやすいように,最初に項目名を出力
while ($line = <>) { # 一行読み込む(別に $line でなくてもいいんですが…)
chomp $line; # 末尾の改行コードを削除する.
if ($line eq "") { # 空白行だったら (文字列の比較は == でなく eq),
next; # なにもしないで次のデータへ.
}
($time, $plant) = split (/\s+/, $line); # 時刻と個体番号に分割
if ($plant eq "0") { # 飛び去ったのなら,
print $time, "\t", $count_plant, "\n"; # 飛び去った時刻と訪花数を出力
$count_plant = 0; # 訪花数をゼロにリセット.
}
else { # 飛び去ったのでなければ,
++$count_plant; # 訪花数をひとつ増やす.
}
}
これまでの知識と,プログラム中のコメントで,ほとんど分かるでしょう.
ひとつだけ新しく出てきたのは,next です. これは for や while などの繰り返し用の構文の中で使う命令で, 繰り返す一連の処理(カッコ {} で囲まれてる部分)を途中でやめて, 次回の繰り返し処理を行うというものです. 次回の処理にさきだって,終了条件のチェック(while なら,while (式) の式が 真か偽かを評価)するので,上のプログラム例では, 次の行を読み込む $line = <> が実行されることになります.
※ next のように繰り返し処理の制御につかう命令として last があります. これは,繰り返し処理をすっかりやめてしまう時に使います.いくつかの 繰り返し構文が入れ子になっている場合には,next も last も,これらを 含む一番内側の繰り返しを一回スキップしたり飛び出したりします.
比較演算子を,数値として比較するのか文字列として比較するのかに応じて 使い分けることに注意. 上の例の if ($plant eq "0") のところは if ($plant == 0) でもOKです. でも,終わりのマーカーとして,たとえば end という文字列を使っているなら, かならず eq を使って if ($plant eq "end") です.
プログラムの流れがすぐには理解できなかったら,データファイルを横目に みながら,まずここでこのデータが読み込まれ,それがこう処理され,次に このデータが読み込まれ… というように, プログラムが実行されるときに処理が進む様子を頭のなかで再現してみましょう.
上のデータを処理した結果は,こんなふうになります.
stay(sec) n_visits 28 3 24 4 .....
このデータは,同じキク個体を再訪することがどのぐらいあるかとか, 再訪のときの滞在時間は1度めのときと比べて短いのかとか,さらにいろいろな 観点から解析できます.もうすぐ説明する配列やハッシュを理解すると, そんな解析のためのプログラムも書けるようになります.
ファイルから読み込んだデータの解析を,もうひとつやってみます. 下の絵はメダマラン(仮名)です.メダマランの開花と結実のデータがあります (としましょう). この植物は,夏にいくつかの花序(花のまとまり)をつくります. 花序の数は1つから,多いもので5つぐらい.それぞれの花序には 1から8個程度の花が咲きます. このうち,秋にちゃんと結実して実になるものは一部です.
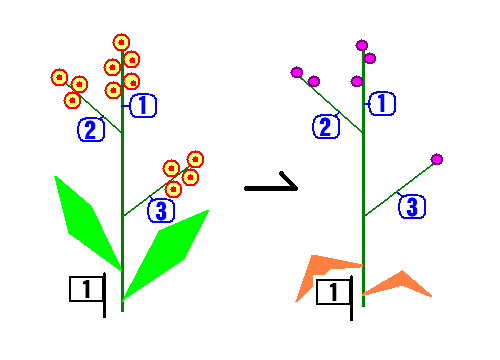
データファイルには,この植物がつけた花の数と実になったものの数を, 花序ごとに記録してあります.
PlantID FlorID flower fruit 1 1 5 3 1 2 3 2 1 3 4 1 2 1 3 1 3 1 8 7 3 2 6 4 3 3 6 3 3 4 3 0 4 1 7 3 4 2 3 1 4 3 2 1 ....
PlantID が個体番号,FlorID は花序(Florescence)の個体内での通し番号, flower は花の数で furit が結実した実の数です.
このデータから,個体ごとに花序の数,花の総数,実の総数を求めたいとします. ぜんぶで 573 個体もある(ことにします)ので,表計算ソフトでどこまでが一個体か 確認しながら作業するのはなかなか大変です.そこで Perl のプログラムです.
# flower_stat.pl メダマランの開花・結実数を求めるプログラム
$line = <>; # データファイルの最初の行を読む(だけ).
$last_plantID = -1; # 最後に読んだデータの個体番号.あり得ない値で初期化.
$n_flors = 0; # 花序(花の集まり)のカウント用の変数の初期設定.
$sum_flowers = 0; # 花の数の積算用
$sum_fruits = 0; # 実の数の積算用
print "plantID\tflrsc.\tflowers\tfruits\n"; # 最初に項目名を出力
while ($line = <>) { # 一行読み込む
chomp $line; # 末尾の改行コードを削除する.
# 個体番号,花序番号,花の数,実の数に分割
($plantID, $florID, $n_flowers, $n_fruits) = split (/\s+/, $line);
if ( !($plantID eq $last_plantID) ) { # 前のデータと同じ個体で_ない_なら
# 前の個体の積算値を表示する(花序が1つ以上ある場合のみ)
if ($n_flors > 0) {
print $last_plantID, "\t";
print $n_flors, "\t", $sum_flowers, "\t", $sum_fruits, "\n";
}
$last_plantID = $plantID; # 現在読み込み中の個体のIDを記憶.
$sum_flowers = $n_flowers; # 積算用変数を,この花序のデータで初期化
$sum_fruits = $n_fruits;
$n_flors = 1;
}
else { # 同じ個体の続き
$sum_flowers += $n_flowers; # A += B は,A = A + B と同義.
$sum_fruits += $n_fruits;
++$n_flors; # 花序数をひとつ増やす.
}
}
# 最後の個体のデータを出力
print $last_plantID, "\t";
print $n_flors, "\t", $sum_flowers, "\t", $sum_fruits, "\n";
一個体のデータを積算していって,その個体のデータが全部そろったところで花序数, 花の総数,実の総数を出力しています.
はじめの例だと,ハナマルギクの個体番号が0のデータがあれば, そこまででひとまとまりだとすぐ判断できました. こんどの例では,データファイルの性質上,どこまでが1個体分のデータかは ひとつ先のデータを読まないと分かりません(違う個体番号がでてきたら, その前までがひとかたまりだったと分かる). そこで,現在読み込み中のデータの個体番号を $last_plantID に記憶しておいて, 次のデータを読んだときにその個体番号と $last_plantID とを比較しています. if ( !($plantID eq $last_plantID) ) のところです.
! は,そのあとの式の真偽を否定して,真と偽をひっくり返します. eq は文字列が等しかったら真,違ったら偽となります. というわけで,前回のデータの個体番号と異なる個体番号が出てきたら, if () のうしろのブロック内の処理が実行されます.
データファイルを最後まで読み終わって while () {} のループ(繰り返し)を 終了したあと,最後の個体のデータを忘れずに出力します. 最後の個体にとっては「次の個体のデータ」が存在しないので, while ループ中では出力されません.データが順次読み込まれて処理される手順を追い ながらプログラムをよく読んで,このことを確認してください.このように, データの最初だの最後だのといった境界付近の扱いには注意が必要です. ちょうど 次のページで, プログラムにひそみがちな間違いについて解説します.
例のデータを処理した結果はこんなふうになります.
plantID flrsc. flowers fruits 1 3 12 6 2 1 3 1 3 4 23 14 4 3 12 5 ......
リダイレクトを使えばこの出力をファイルに記録できる, というのはもう繰り返すことないでしょう.
花や実の数を積算するところでは,+= という演算子を使ってます. プログラムのコメントに書いてあるとおり,A += B は A = A + B と同じ意味です. += だけでなく,-=, *=, /=, .= などもあります. これらの意味は簡単に類推できますね.
最初のほうで,$n_flors,$sum_flowers,$sum_fruits にゼロを代入していますが, これらの文はなくてもちゃんと動作します. はじめて参照された変数はその場で作られる, その値は未定義値で,数値としてはゼロと評価される, というルールがあるためです. たとえば $sum_fruits += $n_fruits; (すなわち $sum_fruits = $sum_fruits + $n_fruits;) が最初に実行されるときは,ゼロに$n_fruitsを足したものが $sum_fruits に代入されます. それでもあえてはじめに $sum_fruits = 0; と書いているのは, あとでプログラムを読むときに,意図を読み取りやすくするためです.
ところで,人はまちがえるものです.ぜったいまちがえるな! といくら言っても,ある確率でかならずまちがえます. 次のページでは,プログラムのまちがい探し,データファイルのまちがい探しに ついて考えます.