{kind=link}
{kind=link}
| Top Page | プログラミング | R 自動化 目次 | 索引 | 前へ | 次へ |
グラフの重ね描きのしかたを覚えると,複数の線を引いたり, 散布図のうえに回帰直線を引いたりできるようになります. 思いどおりに重ね描きするために注意することをまとめてみます.
※なんだかめんどうだなあ,マウスでこちょこちょやるグラフ作製ソフトのほうが 簡単だなあ,という気がしてきたら,もういちど第4章の 最初のところ,「プログラムでグラフを描くメリット」を読んでみてください. もしかしたら,ちょっとやる気が戻るかもしれません.
すでに前に書いたように,作図関数には高水準作図関数と 低水準作図関数がありました.この二つのグループの関数の特徴のうち, とくにグラフを重ね描きするときに重要になる点を表にしてみます.
| 作図関数の種類 | 関数の例 | 座標系 | 既存画面の消去 |
|---|---|---|---|
| 高水準 | plot, hist, curve 他 |
|
|
| 低水準 | lines, points, text, segments, legends, rug 他 |
|
|
座標系の設定というのは,横軸と縦軸それぞれの最小値,最大値を いくつにするかを決めるということです. 高水準作図関数は,与えられたデータの値の範囲から,それらがうまく おさまり,かつ軸の両端が中途半端な値にならないように,座標系を 設定してくれます.
高水準作図関数は,ふつうは前のグラフを消して新しい図を書きます. けれども,描画前に par(new=T) として,グラフィックパラメータ new にT(真) を設定すると, まっさらな作図デバイスが用意されたものと思って,消去作業をしません. ただし,そこに何が描かれているかはいっさい関知しない(なにせ白紙だと思っている)ので, 前の作図のときの座標系も知りません. ですから,同じ座標系でプロットを重ねたいなら,座標系を明示的に指定してやる必要があります.
前のページで, t <- read.table('temperature.txt', header = TRUE) で読み込んだデータを使って,以下のことを試してみる これで,plot で重ね描きするには工夫が必要だということを実感する.
なお,一部の高水準作図関数(curve など)では,add という引数を設定可能です. これを add =T と真に設定して作図関数を呼び出すと,画面の消去をせず,座標系の再設定も せずに重ね描きしてくれます.curve は,データをプロットしたあと,これにあてはめた 式のグラフを重ね描きするような場合に便利です. くわしくはあとで説明します.
うえで整理した作図関数の特性を踏まえると,いくつかの基本的な方針がたてられます. ここでは3つの方針を紹介します.
以下では,方法1から方法3の例をそれぞれ紹介します.
方針1のやりかたで, 'temperature.txt' のデータを使って,3地点(Site01,Site02,Site03) の温度データの一年間の変化を,一枚のグラフに書いていみます.以下のコードを実行して みましょう.
なお,描画画面を表示したままいろいろパラメータ設定を変えて試していると, 前のパラメータ設定が残っていて思わぬ結果になったりします. まず dev.off() で画面を閉じてからはじめると,こうした混乱を避けられます.
t <- read.table ('temperature.txt', header = TRUE) # データの読み込み
# 縦軸の範囲を指定して,折れ線グラフを描く.
plot(t$day, t$Site01, type = 'l', ylim = c(-10, 30),
col = 'black', xlab = 'Day', ylab = 'Temperature')
par(new = TRUE) # 上書き
plot(t$day, t$Site02, type = 'l', ylim = c(-10, 30), # 縦軸の範囲は前の図と同じ.
col = 'blue', xlab = '', ylab = '') # 軸のラベルが重ならないように '' を設定
par(new = TRUE) # 上書き
plot(t$day, t$Site03, type = 'l', ylim = c(-10, 30), # 縦軸の範囲は前の図と同じ.
col = 'green', xlab = '', ylab = '') # 軸のラベルが重ならないように '' を設定
この例で,xlim の設定をしていないのは,3回の描画でいずれも t$day を横軸にしている おり,plot が自動的に設定する軸の最小値,最大値も共通になると考えられるからです. そのほかは,とくに新しく説明するべきことはありません.
縦軸の範囲を c(-10, 30) のように具体的な値で与えていますが,これもデータによって プログラム中で決められればそのほうが便利ですね. それでこそプログラムが生きます. そういう方法は,あとからいろいろ出てきます.
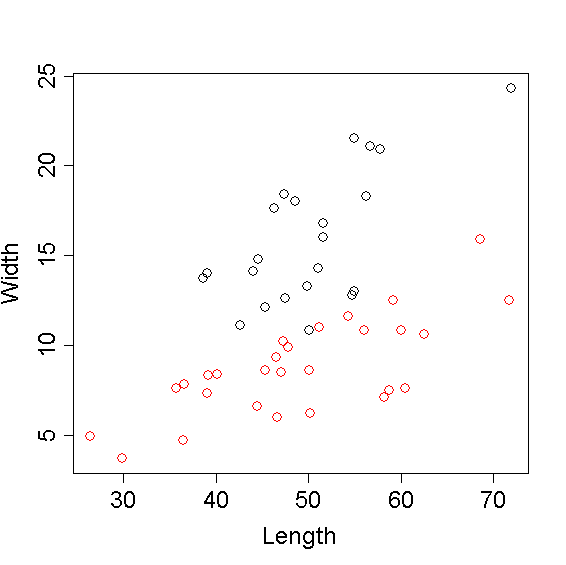
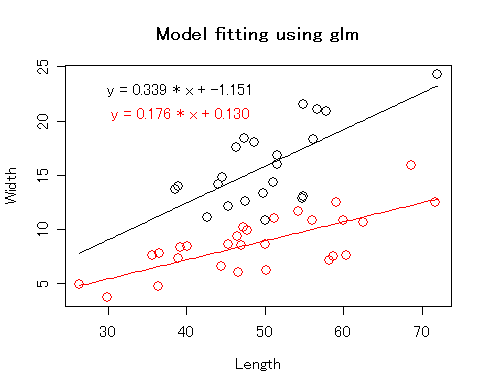
以前に使った len_width.txt のデータで,一枚のグラフに2種類の点をプロットする.
> できあがり参考例
> プログラム例 (まずは見ないで書いてみること)
最初の表で整理したように,低水準作図関数は自分では軸のスケールを設定しません. すでに設定された座標系のなかで作図します. 上の練習で使った d.sp1 と d.sp2 を,低水準作図関数 points を使って プロットしてみます. points は,長さがおなじ二つのベクトルをうけとって, それぞれを縦軸,横軸の値とみなして点を配置する関数です. なんだかplotと同じみたいですが, plotはすでに説明したように総称的関数で,与えるデータしだいで いろんなグラフを描きますし,高水準作図関数ですので,データの値の範囲にもとづいて 自分で軸をきめます.さらに,軸を描いたり,軸ラベルを描いたりしてくれます. それに対してpointsは,点を配置することしかしません.
points と plot それぞれの特徴を生かして,組み合わせてみます.
d <- read.table('len_width.txt', header = TRUE)
d.sp1 <- d[d$sp == 'Sp1',]
d.sp2 <- d[d$sp == 'Sp2',]
#type = 'n' で,プロットはせず軸やラベルだけ描く.
plot(d$len, d$width, type = 'n', xlab = "Length", ylab = "Width")
# それぞれの種の点をプロット.色は番号で指定.cex で大きめの点に.
points(d.sp1$len, d.sp1$width, col = 1, cex = 1.5)
points(d.sp2$len, d.sp2$width, col = 2, cex = 1.5)
> できあがり参考例
plotには,データに応じた座標系を決めて軸やラベルを描くという 仕事だけさせています.種ごとに分けずにすべてのデータを渡しているので, 全部のデータがおさまりきるように座標系を決めてくれます.
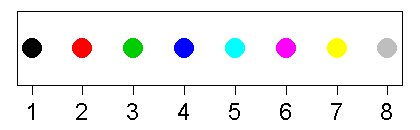
plot が用意してくれた座標系のなかに, points でそれぞれの種の点をプロットしていきます. シンボルは同じ(ディフォルトの○)ですが,色(col)をそれぞれ番号で指定しています. 色にはこのような指定も使えます.1番から8番まであって,色との対応は下の図のとおり です.
この例では,Sp1 と Sp2 という2種類の種のデータがあるという前提の書き方を していますが,何種類あって,それぞれなんという名前かをデータから判断するように 書ければもっとプログラムらしくなりますね.そういう技は次のページで出てきます.
また,このように複数種の点や線をプロットした図では,凡例も書き加えたく なります.凡例は,legend という低水準作図関数で書込みますが, これについても次のページで説明します。
plot で座標系だけ決めて,あとはすべて低水準作図関数を駆使して 作図したいというような場合,plot に渡したいデータはなにもありません. でも,plotはなにもデータを渡さないと文句を言って仕事をして くれないので,ダミーのデータを渡します.たとえば,
plot(0, 0, type = 'n', xlim = c(0, 100), ylim = c(0, 100), xlab = '', ylab = '')
とすれば,プロットするべきデータとしては (0, 0)の一点だけを渡す,でも type = 'n' なのでそれも実際にはプロットされず,x軸,y軸とも 0から 100 の座標系と枠の線だけが 用意される,ということになります. 枠の線も不要なら, axes という引数に F (FALSE,偽)を設定します.
R には、 この章で紹介しているpointsやtext、 あとの章で紹介するlines(線を引く)やlegend(凡例を書く) のほかにも、様々な低水準作図関数があります。 四角形を描くrect、多角形を描くpolygon、 軸を描くaxis などです。 これらを活用すれば、お仕着せではないグラフを自由自在に描くことができるでしょう。 ぜひ、ヘルプなどで使い方を調べて見てください。
一部の高水準作図関数は,add という引数を設定可能です. add が T(TRUE) だと,画像の消去や座標系の設定はしません. 直前に設定せれた座標系のうえで描画します.
その例として,二次元の散布図に,回帰直線を重ねてみます. 回帰直線を求めるのには,glm を使ってみます. glm は,一般化線形モデル(generalized linear model) のあてはめを行う関数です. 一般化線形モデルは,まだなじみがないかた,名前だけは聞いたことがあるけど というかたも多いかと思います. 包括的かつ初心者むけの説明がなかなかないのですが, 使用例は増えつつあります.
もっとも単純な場合には,ふつうの直線回帰と同じことをしてくれますが, 直線回帰をおこなうに当たっての仮定や制約を可変にして, より一般性の高い統計モデルを求めることができます.
このページでは統計解析手法の解説はしません(できません)から,詳しい説明は ほかにゆずって,まずはもっとも簡単に直線回帰モデルのあてはめをしてみます.
あてはめる統計モデルには独立変数ひとつの一次式を書いて, あとは特別になにも指定しなければ,ふつうの直線回帰の条件 (誤差は正規分布に従い,その分散の大きさは一定)で統計モデルをあてはめてくれます.
d <- read.table('len_width.txt', header = TRUE)
lf <- glm(d$width ~ 1 + d$len)
glmには,どの変数を,どの変数で説明したいかを 表現した式をわたします. y = b + ax という形で,x を使って y を説明(予測,推定)したいなら, y ~ 1 + x のように書きます. ~ の左側の変数を,~ の右側の形をした式で説明したい,という意味です. 1 は定数項があるよという意味( 0 にすれば定数項なし), x は x の一次の項も 欲しいという意味.全体で,y を ax + b の形の一次式で推定する統計モデルを 作ってくれ,という意味になります.
上のプログラムでは,d$width ~ 1 + d$len という式をわたしていますが, これは d$width を d$len の一次式(定数項あり)で推定する式を求めたい,という意味です. このあてはめの結果がしまわれたオブジェクトを lf に代入しています. このlf の内容を見てみましょう.入力画面で単に lf と入力すると, このようなものが表示されます.
Call: glm(formula = d$width ~ d$len + 1) Coefficients: (Intercept) d$len -0.06156 0.24132 Degrees of Freedom: 49 Total (i.e. Null); 48 Residual Null Deviance: 1113 Residual Deviance: 848.8 AIC: 289.5
最後の AIC は赤池の情報量基準で,モデルがどのぐらいよくデータに 当てはまっているかを表すものです. (参考: 群馬大・青木さんの統計学用語辞典中の AIC). ここでは詳しく説明しません.
Coefficients: の下, (Intercpet) と d$len の ところの数値が,それぞれあてはめた直線の切片と傾きの値です. 第3章の,相関関係の計算結果を見たところを思い出しつつ, lf に含まれる内容を取り出してみましょう.まず,どんな名前のデータがあるかを, namesで調べてみます.
names(lf)とすると,
[1] "coefficients" "residuals" "fitted.values" [4] "effects" "R" "rank" [7] "qr" "family" "linear.predictors" [10] "deviance" "aic" "null.deviance" [13] "iter" "weights" "prior.weights" [16] "df.residual" "df.null" "y" [19] "converged" "boundary" "model" [22] "call" "formula" "terms" [25] "data" "offset" "control" [28] "method" "contrasts" "xlevels"
のように,30種類ものデータを含んでいることがわかります.このなかで,あてはめたモデル の傾きと切片は,最初の lf$coefficients に入っていそうです.はたして,
lf$coefficients
と入力すると,
(Intercept) d$len -0.0615620 0.2413217
と表示されます.名前のついた2つの数値データからなるベクトルですね. ふたつの要素それぞれは,d$coefficients[1], d$coefficients[2] のように指定します.
モデルをあてはめることができたら,それを表す線をグラフに書込みます. これには curve という高水準作図関数を使います. 引数に式を与えると,その式のグラフを描いてくれる関数です. たとえば,
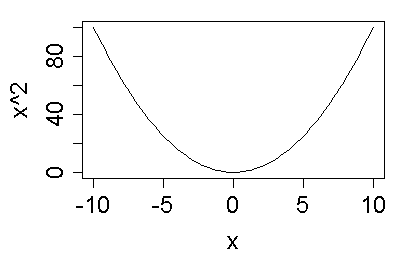
curve(x^2, from = -10, to = 10)
と入力すると,x が -10 から 10 の範囲で x^2 (xの二乗)のグラフを描いてくれます (>作図例).from と to が,x の範囲を設定する引数です.
縦軸のスケールは勝手に決めてくれるし,軸も描いてくれるし,たしかに高水準作図関数です. この関数を add という引数に T(TRUE) を設定して呼び出すと, 画面の消去をせず,すでに存在する座標系のなかにグラフの線だけが描かれます. まるで低水準作図関数のような振る舞いです (といっても,式からグラフを描くのはやはり高水準な仕事ですが).
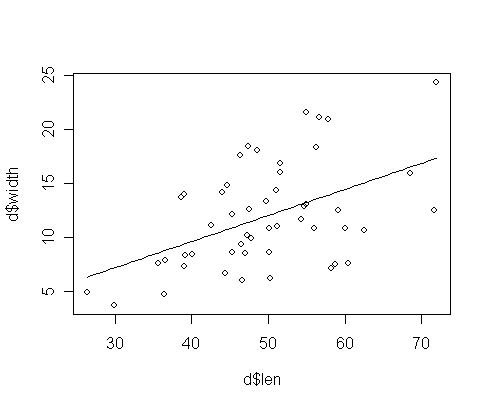
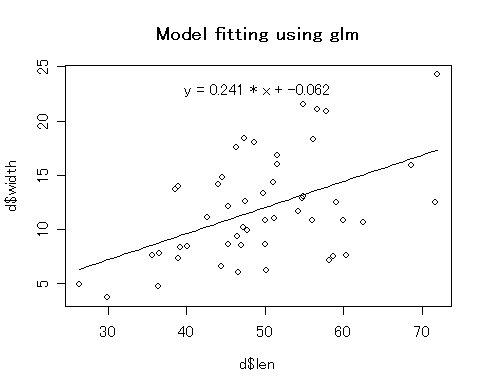
これを使って,上で求めた直線回帰モデルを表す線を,散布図の上に重ねて描いてみます. x の範囲は,関数 minとmaxで求めています.
d <- read.table('len_width.txt', header = TRUE)
plot(d$len, d$width) # 散布図を描く
lf <- glm(d$width ~ 1 + d$len) # モデルのあてはめ結果を lf にしまう.
cf <- lf$coefficients # あてはめたモデルの係数を変数 cf にしまう.
curve(cf[1] + cf[2] * x, from = min(d$len), to = max(d$len), add = TRUE)
> できあがり参考例
せっかく求めた式の切片と傾きも,グラフ中に書き込むことにしましょう. これには,text という低水準作図関数を使います. 文字列を配置する場所のx座標とy座標,そして文字列の内容をわたします. (そのほかにもいろいろな設定ができます. くわしくは help(text) で調べてください).
さて,ここでちょっと困るのが座標の指定です.たとえばグラフの上のほうのまん中に 書きたいとして,そこの xy 座標を知らないと指定のしようがありません. 点をプロットしてから眺めればおおよそ分かることですが,それではプログラムで 自動化するのには不都合です. となると,今,座標系はどうなってるのか,x軸,y軸の両端の値を調べてから, 適当な座標を計算してやればよさそうです.軸の両端の値は,グラフィックパラメータ usr にしまわれてきます.
par('usr')
とすると,たとえば
[1] 24.580 73.720 2.876 25.124
のように4つの値が表示されます.はじめから順に x軸の最小値,最大値, y軸の最小値,最大値です.この,4つの数値データが並んだベクトルを一度 変数にしまってから,その値を使って適切な配置場所の座標を計算することに しましょう.たとえば,
par('usr') -> usr
x <- (usr[1] + usr[2]) / 2 # x軸のまん中
y <- (usr[4] - usr[3]) * 0.9 + usr[3] # y軸の下から 90% のところ.
のようにして,適当な座標を決めます. glm で求めた式の内容は, 第3章のなかの「計算結果をファイルに記録する」のところで紹介した sprintfをつかって文字列にします.
eq <- sprintf('y = %.3f * x + %.3f', cf[2], cf[1])
%.3f というのは,実数として,小数点以下3ケタまで表示せよ,という書式指定子です. これを実行すると,変数 eq には "y = 0.241 * x + -0.062" というような文字列が記録されます.
ここまで準備ができれば,あとは text を呼ぶだけです. ついでに,グラフ全体のタイトルも書きこみましょう. これは,plot 関数で main という引数に設定します.
plot(d$len, d$width, main = "Model fitting using glm") # 散布図を描く
ここまでのプログラムをひとつにまとめてみます.
d <- read.table('len_width.txt', header = TRUE)
plot(d$len, d$width, main = "Model fitting using glm") # 散布図を描く
lf <- glm(d$width ~ 1 + d$len) # モデルのあてはめ結果を lf にしまう.
cf <- lf$coefficients # あてはめたモデルの係数を変数 cf にしまう.
curve(cf[1] + cf[2] * x, from = min(d$len), to = max(d$len), add = TRUE)
par('usr') -> usr # 現在の座標系を取得
x <- (usr[1] + usr[2]) / 2 # x軸のまん中
y <- (usr[4] - usr[3]) * 0.9 + usr[3] # y軸の,下から 90% のところ.
eq <- sprintf('y = %.3f * x + %.3f', cf[2], cf[1])
text(x, y, eq)
> できあがり参考例
だいぶ盛り沢山の内容でしたが,なかなかりっぱなグラフが描けました. これまでの知識を使ったり,さらにいろいろ調べたりすれば,さらに 見栄えのよいグラフが描けるでしょう.
> できあがり参考例
> プログラム例 (まずは見ないで書いてみること).
これまでの知識を総動員する練習です. ぜひ試してみてください.
このように複数の種類のデータがプロットされているグラフでは,凡例も 表示させたいところです.凡例の描画には専用の関数が用意されています. それについては次のページで紹介します.
この章の最後の節は,グラフを重ねるのではなく,並べる話です.
前の章で, デバイス領域,作図領域,プロット領域について簡単に紹介しました. デバイス領域をいくつかに区切って,その区画をじゅんに作図領域にして グラフを書いていけば,一枚の'紙' にいくつものグラフを並べることができます. 同じ形式のグラフをたくさん並べるのにも使えるし, 関連がある複数のグラムを見比べるために使える方法です.
作図領域を par(fig = c(....)) で指定しながらグラフを描いていくこともできますが, もっと簡単に,デバイス領域を 2×2に区分して使いますよ,とか, 3×4にして使いますよ,と設定すると,新しいグラフを描くごとに自動的に 作図領域をずらしてくれる機能があります.
そのためには,parで mfrow あるいは mfcol というパラメータに, たてに何区画,よこに何区画という2つの数値からなるベクトルを設定します. mfrow を使うと,左上から右へ描き進め,一行目が一杯になったら二行目へ,と進みます. また, mfcol を使うと,左上から下へ描き進め,一列目が一杯になったらニ列目へと 進みます. たとえば3行4列にグラフを並べる,描き進む順序は1行目,2行目…なら, par(mfrow = c(3, 4)) と設定します.
ところで,この方法でグラフを並べていって,一枚の'紙'がいっぱいになった場合, なにが起こるかはデバイスによります. 描画画面や,png,jpg などのビットマップ画像の場合は, 次のグラフを描くときに一度すべてが消去されてしまいます.
一方,pdf や postscript のように,ページという概念があるデバイスでは, 新たなページが足されて,そこに描きこまれていきます.
※ wmf (ウィンドウズメタファイル)では,もう描けない状態になると ファイルを作れませんとメッセージが表示されます.さらに, R のプログラム自体が停止してしまったりするようです.
したがって,全部で何個のグラフがあるのか,一枚の '紙' に入りきるか どうか分からずに画像ファイルを作る場合には,デバイスによっては それなりの処理が必要です. 複数枚のページにわたって描いてくれない デバイスの場合には,'紙' の容量一杯(あるいはその前でも きりのいいところ)までグラフを描いたら一度 dev.off() し, あらたに画像ファイルのデバイスドライバを起動します. 当然,このファイルは前に作ったファイルと別の名前にしないといけません. 同じ名前だと,先に作ったファイルの内容は上書きされて消えてします.
{kind=link}
{kind=link}
{kind=link}
{kind=link}