| Top Page | プログラミング | R 自動化 目次 | 索引 | 前へ | 次へ |
この章では,条件分岐と繰り返しを使って,前に作った作図プログラムをさらに 柔軟なものにしてみます.3地点のデータがあるとか, 登場する生き物の種類は2種類だとか,はじめから決めてしまったプログラムではなく, 読み込んだデータからこういう情報ととりだして, それに応じてグラフを描くようなプログラムにします.
まず,毎日の日平均気温1年分のデータのグラフを描くプログラムを改良します. 改良点は,
データの値の範囲に応じて軸の範囲を決めるのは, 前の章 の最後に 紹介した range で簡単にできます.
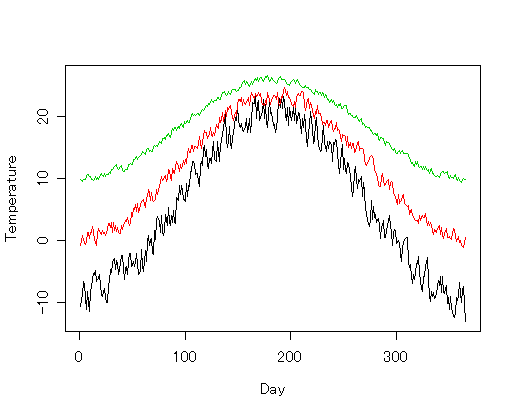
温度のデータ 'temperature.txt' の1列目は日付(初日から何日目か)ですから, この列の値の範囲をしらべて,横軸の範囲の設定につかいます. また,縦軸(温度)の範囲は,range(t[2:ncol(t)])で求まるのでした (忘れていたら前の章を復習). これらを plot の xlim や ylim 引数に渡せば データに合せて座標系の指定ができます.
座標系を作るまでのプログラムはこんなふうになります.
t <- read.table ('temperature.txt', header = TRUE) # データの読み込み
# 軸の範囲を指定して,座標系を設定する.
plot(0, 0, type = 'n', # type = 'n' なので,渡すデータはなんでもよい.
xlim = range(t[1]), # 横軸の範囲
ylim = range(t[2:ncol(t)]), # 縦軸の範囲
xlab = 'Day', ylab = 'Temperature')
線を引く lines は,x 座標がならんだベクトルと y座標がならんだベクトルを受けとります. i列めのデータがならんだベクトルは, t[[i]] です(t[i]とすると, ベクトルではなくて,列をひとつだけ持つデータフレームになってしまうので注意). 一列目の日付のデータ(t[[1]])を横軸に,それ以降の各列の温度データを縦軸にとって グラフを描きます. for 文を使えば,全部の温度データのグラフが一度に描けます.
for (i in 2:ncol(t)) { # 2列めから最後の列まで
lines(t[[1]], t[[i]]) # 日付を横軸に,温度を縦軸に線グラフ
}
ついでに線の色も変えましょう.lines の, 線の色を指定する引数 col を使います. col に渡す値を i によって変えれば,一列ごとに違う色の線が書けます. 2列目からが温度データなので, i は 2 からはじめて1ずつ増えていきます. 1番めの色(黒)からスタートするために, col を i ではなく i - 1 としてみます.
for (i in 2:ncol(t)) { # 2列めから最後の列まで…
lines(t[[1]], t[[i]], col = i - 1) # 色を指定して折れ線を描く
}
ここまでを全部あわせるとこうなります.
t <- read.table ('temperature.txt', header = TRUE) # データの読み込み
# 縦軸の範囲を指定して,折れ線グラフを描く.
plot(0, 0, type = 'n', # type = 'n' なので,渡すデータはなんでもよい.
xlim = range(t[1]), # 横軸の範囲
ylim = range(t[2:ncol(t)]), # 縦軸の範囲
xlab = 'Day', ylab = 'Temperature')
for (i in 2:ncol(t)) { # 2列めから最後の列まで
lines(t[[1]], t[[i]], col = i - 1) # 色を指定して折れ線を描く
}
これを実行したときに描ける絵の例を載せておきます. > できあがり参考例
なお,lines では,col 引数で色を指定できるほか, lwd という引数で線の太さを指定したり(1がディフォルト), lty という引数で線の種類を指定したり (ディフォルトの 1 で実線,ほかに破線,点線など) できます.これらはどれかひとつの引数だけ使ってもよいし, 複数の引数に同時に値を設定することもできます.
もう一手間かけて,凡例をつけることにしましょう. これにはlegend という低水準作図関数を使います. まずは help(legend) で,使い方を見てみてください. いろいろな引数が並んでいますが,要点は,
ということです.
並べて書きたい文字列は,たとえば c('sun', 'moon', 'earth') とように書き連ねて もよいし,colnames(t) とすればデータフレームの各列の名前を指定できます.
色を指定する場合,番号で表現するなら,たとえば col = c(1,2,3,4,5) とか,あるいはもっと簡単に col = 1:5 と書けば, 1番めから5番めの文字列に対応して,1番から5番の色が並びます. 番号と色の対応は, 第6章 に出てきました.
シンボル,色,線のタイプが複数設定されたら,どれも同時に変えていきます. col = 1:5, lty = 1:5 なら,色が1番で線の種類が1番,色が2番で線の種類が2番,… というぐあいに並びます.
col = 1:5, lty = 1 のように,どれかの引数(この場合は lty)にあたえる ベクトルの要素数が足りなかったら,指定された値を繰り返し使います. この場合なら,線はすべて1番(実線)で,色は1番から5番まで, ということになります.
シンボルの種類は pch という引数で指定します. これも,番号で指定できます.番号と形の対応は 第5章 に出てきました.
凡例の配置場所は,x, y 座標で指定します. 適切な場所を指定するには,いま座標系がどうなっているかを知る必要があります. 座標系は直前に呼んだ高水準作図関数が決めてくれています. 縦軸,横軸の最大,最小は, usr というグラフィックパラメータに記憶されているので, これを調べて使うという手もあります. 第6章 で,glm であてはめたモデルの式を text で図中に書き込むときにはこの方法を使いました.
いちいち座標を調べるのが面倒であれば,x座標の替わりにキーワードで指定することもできます. 使えるキーワードは "bottomright", "bottom", "bottomleft", "left", "topleft", "top", "topright", "right" と "center" です.それぞれの意味は明らかですね
これらのキーワードで指定すると,凡例はプロット領域の隅に密着して描かれますが, 余白を指定することもできます.見栄えのよい凡例の書き方については 12章でも説明しています.
さらに別の方法は,分かりやすいような座標(たとえば縦軸,横軸ともに 0 から 1 ) に変えてしまってから凡例を描くというものです. 凡例は一番最後に描くことにすれば,これでもまったく問題ありません. 座標系を設定するには, par を使って, グラフィックパラメータ usr に 横軸の最小,最大,縦軸の最小,最大が並んだ ベクトルを渡します.
par(usr = c(0, 1, 0, 1))
とすれば,縦軸,横軸ともに 0 から 1 となります.あとは,0から1の範囲の適当な値を 座標として指定して,legendを使って凡例を描きます.
説明が長くなりました.実際に描いてみましょう.さきほどの温度のグラフを 描くプログラムに,凡例をいれる命令を書き加えます.
t <- read.table ('temperature.txt', header = TRUE) # データの読み込み
# 縦軸の範囲を指定して,折れ線グラフを描く.
plot(t$day, t$Site01, type = 'n',
xlim = range(t[1]),
ylim = range(t[2:ncol(t)]),
xlab = 'Day', ylab = 'Temperature')
for (i in 2:ncol(t)) { #
lines(t[[1]], t[[i]], col = i - 1)
}
# 色の設定は lines での設定と対応させることに注意.
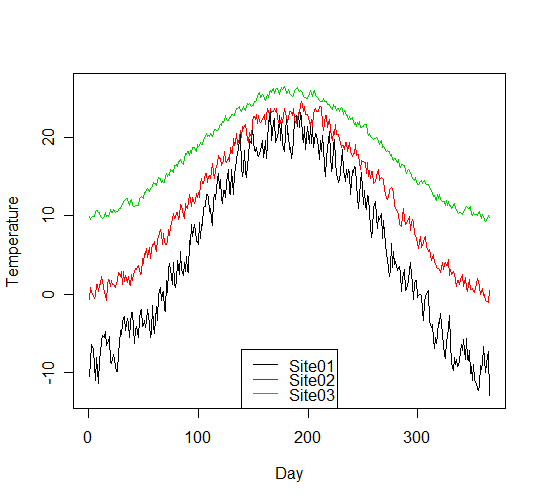
legend("bottom", legend = colnames(t[2:ncol(t)]), col = 1:(ncol(t) - 1), lty = 1)
これを実行すると,こんな絵が書けます. > できあがり参考例
凡例を囲む箱の左上の角が,legend に指定した座標に配置されます.
データフレームを構成する各列はそれぞれなんらかの測定項目や特性に対応するもの, 各行はそれぞれひとつのサンプルに対応するものと見ることができます. データフレームに読み込んだデータのうち,数値でない文字列データからなる列は, 因子として扱われます (関数 factor を使えば数値データの並んだ列を因子化することもできます). 因子は,サンプルを種類分けするキーのようなものです.
たとえば,データファイル len_width.txt の場合, 生物の種類名(species) を表す sp という名前の列がありました. この列には Sp1 という文字列と Sp2 という文字列が登場します. read.table で読み込んだデータフレームでは,この列は因子として扱われます. 因子の列中にどんな種類の要素があるかを知るには,levels という関数を使います.
d という名前のデータフレームにこのファイルのデータを読み込んだところで, levels(d$sp) と入力すると,
[1] "Sp1" "Sp2"
のように,二種類の要素からなるベクトルが表示されます.
第6章 で, len_width.txt のデータを使い,len と width の関係を Sp1 と Sp2 のデータ それぞれについて別のシンボルでプロットしました.このプログラムでは, Sp1 という種類と Sp2 という種類のデータが含まれるものとはじめから決めて 書きました.
これを改良して,全部で何種類あるのか,それぞれの名前はなんなのかを 決めてしまわず,読み込んだデータに応じて処理できるようにしてみます. こんどは,forの構文による繰り返しを,登場する全部の 種類についてひとつづつ処理するために利用します.
d <- read.table('len_width.txt', header = TRUE)
levels(d$sp) -> sp.list # sp.list は,d$sp に出てくる因子のベクトル
length(sp.list) -> n.sp # このベクトルの長さ(要素数)がすなわち種数
#type = 'n' で,プロットはせず軸やラベルだけ描く.
plot(d$len, d$width, type = 'n', xlab = "Length", ylab = "Width")
# それぞれの種の点をプロット.色は番号で指定.cex で大きめの点に.
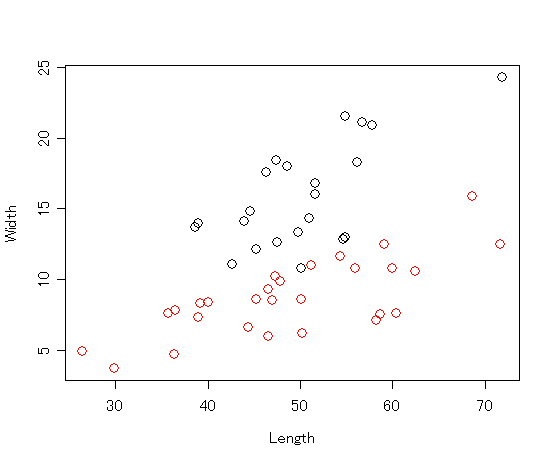
for (i in 1:n.sp) { # 各種類ごとに…
d.sub <- d[d$sp == sp.list[i], ] # i 番めの種類だけからなるデータフレームを作る.
points(d.sub$len, d.sub$width, col = i, cex = 1.5) # 色を指定して i番目の種類をプロット
}
これまでに勉強したことを思い出しながら読んでみましょう. i 番めの種類のデータのみを含むデータフレームを作るところは, 第2章の「条件を指定して行を選ぶ」の節を参照.
これを実行すると,こんなグラフが書けるはずです. > できあがり参考例
上の例では,ふたつの種 Sp1 と Sp2 のどちらかの値をとる列 d$sp のデータによって, データフレームオブジェクト d の一部の行だけを取り出してから,描画をしていました. こうした手間をかけずに一気に種により色分けして plot で作図する方法もあります. 下のようなプログラムを実行してみてください.
d <- read.table('len_width.txt', header = TRUE)
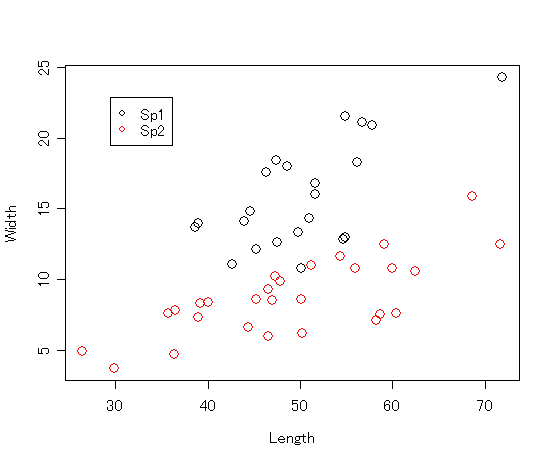
plot(d$len, d$width, type = 'p', col = c(1, 2)[d$sp], cex = 1.5, xlab = "Length", ylab = "Width")
ここでのポイントは,col = c(1, 2)[d$sp] のところです. 色番号を指定する col に,ベクトル c(1,2) のうしろに [d$sp] と書き加えたものを与えています. 少々ややこしいのですが,順を追って説明します.
まず,ベクトル c(3, 5)[2] のように,ベクトルのうしろにひとつの数値を書くと, それに対応する要素(たとえば [2]なら2番めの要素 5 )を意味します. このようにベクトルのうしろに [ ] で囲って '何番めの要素' かを指定するものを 添字(そえじ)と呼びます.この添え字としてベクトルを書くこともできます.
c(3, 4)[c(1, 2, 2, 1)] [1] 3 4 4 3
この例では,ベクトル c(3,4) の添え字として c(1, 2, 2, 1) を指定しているので, 1番めの要素,2番めの要素,2番めの要素,1番めの要素 と4つの要素が表示されています.
こんどは [d$sp]について考えます.データフレーム d の中で, sp という列には種の名前 ("Sp1" か "Sp2")が入っています.これらは一見するとただの文字列ですが, すでに説明したようにデータフレーム中では因子として扱われます.因子は,文脈によっては 「n番めの因子」という数値として解釈されます.むりやり数値として解釈する関数 as.numeric に d$sp を渡してみると,
as.numeric(d$sp) [1] 2 1 1 1 2 2 2 2 1 2 1 1 2 2 2 2 1 1 1 1 1 2 2 1 2 2 1 1 2 2 2 1 2 2 2 2 2 2 [39] 1 1 2 1 1 2 1 2 2 1 2 1
のように,1行めから順番に,1番めの因子 "Sp1" なのか,2番めの因子 "Sp2" なのかに 応じて 1 と 2 が並んだベクトルを返します.
ベクトルの後ろの添え字として因子を渡すと,やはり as.numeric に渡されたときのように 数値のベクトルとして評価されます.そのため, c(1, 2) [d$sp] と書くと, c(1, 2)[c(2, 1, 1, ....)] のように解釈され,色を指定する引数 col に、 50個(データが50個あるので)の色指定が並んだベクトルを渡したことになります.
plot 関数は、ひとつひとつのデータをプロットするに当たって、これらの色指定を順次参照して 色を決めてくれます。というわけで、それぞれのデータは、d$sp の値に応じて色分けして プロットされることになります。
だいぶ長くなってきましたが,最後にもうひとつ.繰り返しを使って列内の 各データに順次アクセスする(値を使う)練習をしてみます. 使うのは,温度のデータ 'temperature.txt' です.
このデータから,積算温度が日々増えていくようすをグラフにしてみます. 積算温度とは,一定時間ごとの温度を足しあわせていったもので,たとえば 毎日の日平均気温を足していったり,1時間ごとの温度を足していったりして 計算します.
いろいろな生物現象が,(少なくとも見た目は)積算温度というものに依存して 起こることが知られています.春先の木の芽吹きなどはその例です. なお,ある温度以下の低温は生き物にとっては意味がないとして, その境界温度を気温から引いたものがプラスのときだけ積算する,という方法がよく使われます.
まずは,毎日の温度データがならんだベクトルと,境界温度とを受けとって, 日々の積算温度(degree day と呼びます)を計算する関数を書いてみましょう.
# 渡された温度データのベクトルを,最初からひとつづつ積算して積算温度のベクトル
# を作製する関数.積算温度を計算するときの基準温度 threshold はディフォルトでは
# 5 度となる.
calc.deg.day <- function(t.data, threshold = 5)
{
x <- t.data[1] - threshold # 1 日めの積算温度
if (x < 0) {
x <- 0
}
deg.day = c(x) # 要素がひとつのベクトル
for (i in 2:length(t.data)) { # 2日めからの温度
if (t.data[i] > threshold) { # 基準温度より高ければ…
x <- (t.data[i] - threshold) + deg.day[i - 1] # 前日までの積算温度に加える.
}
else {
x <- deg.day[i - 1] # そうでなければ,積算温度は前日の値のまま.
}
deg.day <- c(deg.day, x) # 積算温度のベクトルの後尾に x を付け加える.
}
return (deg.day) # t.data の最後まで行ったあと,できたベクトルを返す.
}
関数の定義の最初,
calc.deg.day <- function(t.data, threshold = 5)
のところで,threshold = 5 と書かれています.これは,とくに2番めの引数を 指定しないと,threshold には 5 という値が設定されることを意味しています. これまでも多くの作図関数で引数にディフォルトと違う値を設定したいときだけ 設定するようになっていました.なにも指定しないときのディフォルトの値は, このように関数の定義に書かれたものです.
関数を呼び出すとき,ディフォルトの値が設定されていない引数を指定しないと エラーになります. calc.deg.day の場合,温度データのベクトルを渡さないと エラーになりますが,threshold は設定してもしなくてもよい,何も設定しなければ 5 という値が使われる,ということです.
この関数をそのまま入力画面にコピーするなり,ファイルにしまってから source で 読み込むなりすれば,自作の関数 calc.deg.day が登録されます.
t <- read.table ('temperature.txt', header = TRUE) # データの読み込み
で温度のデータを読み込んだあと(すでに読み込んであれば読み直す必要はありません),
calc.deg.day(t$Site01)とすれば,基準温度を 5度に設定して毎日の積算温度を 計算した結果のベクトルが表示されるはずです.
ここまでできれば,t の各列について積算温度を続けて計算するプログラムは簡単に 書けそうな気がします.たとえば…
t <- read.table ('temperature.txt', header = TRUE) # データの読み込み
n.sites <- ncol(t) - 1 # 測定地点数
for (i in 1:n.sites) { # 各地点について…
calc.deg.day(t[[i + 1]]) # 積算温度を計算する(温度データは2列目から)
}
とすると,すべての地点で積算温度を計算してくれるはずです. でも,計算の結果はどこにも記録されないので,あとから使いようがありませんね. なにかの変数(オブジェクト)にしまっておきたいところです.
そこで,計算結果のベクトルを,最初にデータを読み込んで作ったデータフレームに, あらたな列として加えていくことにします. すでにあるデータフレームに,各列と同じ長さ(要素数)のベクトルを新しい列として 付け加えるには, cbind という関数を使います. c は column(列)の c です. cbind(データフレーム,ベクトル)と書けば,ベクトルがデータフレームの 新しい列として追加されます.
cbind を利用すれば,以下のようなプログラムで各地点の積算温度 の列をデータフレームに加えることができます.
t <- read.table ('temperature.txt', header = TRUE) # データの読み込み
n.sites <- ncol(t) - 1 # 測定地点数
for (i in 1:n.sites) { # 各地点について…
calc.deg.day(t[[i + 1]]) -> dd # 積算温度を計算する(温度データは2列目から)
t <- cbind(t, dd) # データフレーム t に列を加える.
colnames(t)[ncol(t)] <- sprintf("DegDay%02d", i) # 列に名前をつける.
}
追加した列の名前は'適当に'つけてくれる(たとえばベクトルの変数名) のですが,自分で制御できないのは気持ち悪いので,あとからはっきりと指定しています. colnames(t)は t の各列の名前がならんだベクトルで, その ncol (t) 番めの 要素とは最後の列の名前,すなわち直前に cbind でくっつけたものです. これに文字列を代入すれば,データフレーム中の列の名前を変更することができます. 名前の文字列は sprintf で形を整えて作っています.
繰り返しの構文は,上のプログラムでは各地点の積算温度に対応する列を順次作るのに 使っています.また,そのために呼び出している関数 calc.deg.day の中では, すでに見たように,列のなかの毎日のデータに順次アクセスするのに繰り返しの構文を 利用しています.
こうして毎日の温度と積算温度とをしまったデータフレームができたら, さっそくグラフが書きたくなります.これは練習の課題としましょう.
> できあがり参考例
> プログラム例 .関数 calc.deg.day() の定義も含めてある.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}