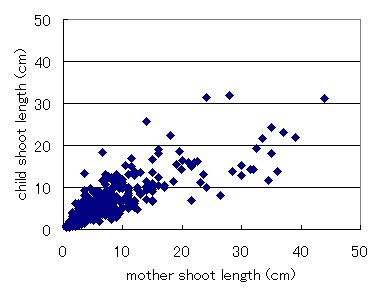
親枝が長いほど,その子枝も長いという全体的な傾向があるようです. ただ,ばらつきが大きくてそれ以上はよくわかりません.. 次に,子枝の長さと親枝の長さの比率を計算して,親枝長に対してプロット してみました.
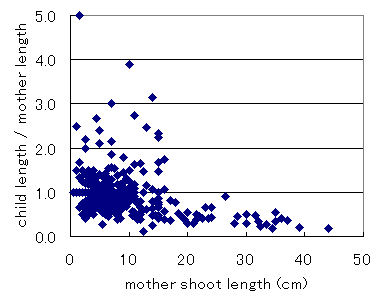
右肩さがりのパターンが見えてきました. つまり,親枝が長いほど,その子枝は親枝よりも短めということです. また,親枝長を固定して考えたときの,子枝長と親枝長の比率のばらつき具合は, どうも大きいほうに尾を引いた関係のように見えます. ためしに,長さの比率の対数をとって見ると,このようになります.
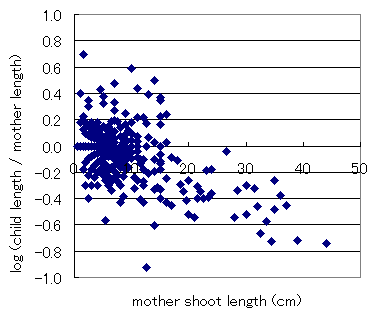
この関係をモデル化の出発点にしてみました. 以下では,親枝の長さをL,子枝長と親枝長の比の対数をQと書くことにします. 上の図の特徴としては,まず,Lが大きいほど,Q の平均値(Qmean)が 小さいことがあげられます.それに加えて,Lが大きいほどQ のバラツキが小さい ような気もします. LとQmeanの関係を直線的だと仮定するのはどうも無理が ありそうなので,パラメータの数が増えて面倒だけど,
Qmean(L) = c0 /(L + c1) - c2 …式(1)
で表現することにします.c0, c1, c2は定数です.
次に,Qのバラツキです.ばらつき方は,いちおう正規分布に従うということに しておきます.この点についてはあとで少し吟味します. Qのバラツキの標準偏差 Qsdは
Qsd(L) = c3 /(L + c4) …式(2)
で表現することにします. 式(1),(2)の5つのパラメータの値を,最尤法で推定することにします. 最尤法については 前のページ で簡単に触れました.
5つのパラメータを動かしながら一番もっともらしい値の組みを探すのは けっこう時間がかかります(私の書いたプログラムのアルゴリズムが あまりに愚直なもんで)が,ともかくお茶を(うんとゆっくり)飲んで待ってれば 結果が出てくる程度の時間で済みました. パラメータの値は以下のようになりました.