| Top Page | プログラミング | R 自動化 目次 | 索引 |
updated on 2014-08-25
統計処理は、たくさんのデータを使って行います。 プログラミング言語の多くは、多量のデータの処理を効率よく記述できる 文法が用意されています。R は、特にそうした機能が充実しています。 たとえば、
a <- c(1, 3, 5) a <- a + 1
と書けば、a の3つの要素すべてに 1 が加えられて、2, 4, 6 となります。
同じことは for ループでもできます。
for (i in 1:3) {
a[i] <- a[i] + 1
}
けれども、このような書き方をするとプログラムが長くなるし、実行時間が余計にかかることもあります (参考: Perl, R, Ruby, C++ で作成したプログラムの実行速度の比較)。
Rでは、for ループを使わずに多量データの一括処理をシンプルに書ける apply 系の関数というものが 用意されています。 apply のほか、tapply, lapply, sapply, mapply などがあります。 これらは慣れないとなかなか使いにくいのですが、使いこなすと気持ちのよいプログラムが書けます。 行列タイプのデータを処理する apply、 データをグループごとにまとめて処理する tapply、 ベクトルやリストに並んだデータを順次処理する lapplyとsapply、 複数のベクトルやリストそれぞれからひとつづつデータをとりだして、それらをまとめて処理する mapply について説明します。
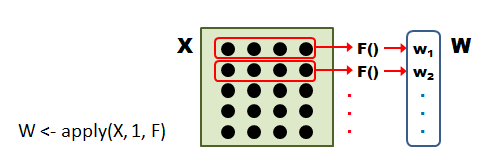
二次元の行列のかたちをしたデータがあって、一行ごとにまとめて関数に渡して処理したい場合、 apply を使います。まずは概念図を見てから、以下の説明を読んでください。 図中の X はデータ、 F はデータを処理する関数です。
temperature_2.txtというファイルを使って試してみます。 内容は1年間の日平均気温のデータです。
Site01 Site02 Site03 -10.5 -0.7 9.9 -8.7 0.9 9.6 -6.5 0.2 9.8 -7.1 -0.2 9.9 -9.1 -0.6 9.9 -11 -0.3 10.4 ...
ヘッダ行+365行、3列のデータです。3列は3つの地点、 365行はそれぞれ1年365日間毎日に対応します。
毎日の3地点の平均気温を求めたいとします。 そのためには、1行(3つのデータ)ごとに関数meanに渡せばよいはずです。 データをデータフレームに読み込んで、以下のように apply を使って計算します。
x <- read.table('temperature_2.txt', header = TRUE)
daily.means <- apply(x, 1, mean)
これで、daily.means というベクトルに 365 日それぞれの、3地点の平均気温がしまわれます。 apply に渡す最初の引数(ひきすう)はデータフレーム(ないしは行列)です。 2番目の引数 1 は、一行ごとにまとめて関数に渡せ、ということを意味します (他の設定については次項で)。 3番目の引数は関数名で、この場合は mean です。 内容を表示させると、以下のようになります。
> daily.means [1] -4.333333e-01 6.000000e-01 1.166667e+00 8.666667e-01 6.666667e-02 [6] -3.000000e-01 1.300000e+00 7.333333e-01 -2.000000e-01 1.166667e+00 [11] 1.200000e+00 2.000000e+00 2.033333e+00 1.500000e+00 1.833333e+00 ...
ためしに mean ではなく sum とすれば3地点の合計が計算されますし、 var とすれば毎日の、3地点の気温の分散が計算されます。
同じデータで、こんどは1列ごとにまとめて関数に渡してみます。 今度も、まずは概念図から。 前と同様、図中の X はデータ、 F はデータを処理する関数です。
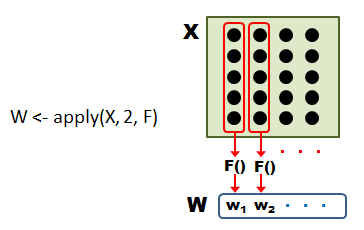
行ごとの場合との違いは、apply に渡す2番目の引数を 1 ではなく 2 にすることだけです。
x <- read.table('temperature_2.txt', header = TRUE)
site.means <- apply(x, 2, mean)
site.means の内容は以下のようになります。
> site.means Site01 Site02 Site03 5.975616 11.956438 17.964658
1 と 2 と、どちらが行ごとでどちらが列ごとか混乱しますが、日本語の「行・列」という言葉の順に、 「1なら行ごと関数に渡す」「2なら列ごと関数に渡す」と覚えてしまいましょう。
なお、apply に渡す関数は、ひとつの値を返すものに限定されません。複数の値のベクトルを返す関数の場合、 apply の結果は行列となります。たとえば値の範囲(上限と下限)を返す関数 range を渡して試してみてください。
d <- read.table('temperature_2.txt', header = TRUE)
day.range <- apply(d, 1, range) # 毎日の、3地点の気温の範囲(365行、2列の行列)
site.range <- apply(d, 2, range) # 各地点での、年間の気温の範囲(2行、3列の行列)
site.range の中身を見ると、たしかに 2行×3列の行列です。
> site.range
Site01 Site02 Site03
[1,] -13.0 -1.1 9.3
[2,] 23.6 24.6 26.6
関数が、ひとつの数値や単純なベクトルではなくリストを返す場合には、 apply はいくつものリストを要素として含むリストを返します。 単純な数値や文字列、論理値しかベクトルや行列にはしまえませんが、 リストにはなんでも(リストでも)しまうことができるので、apply に渡した関数がリストを返すなら、 applyとしては、それらをいくつも並べて返すために、おのずとリストに詰め込むしかない、ということです。
多くの関数では、渡したデータの処理の仕方などを指定する、いろいろなオプションが設定できるようになっています。 apply に渡す関数にオプション指定をしたい場合、apply に渡す引数として、関数の後に続けて書きます。
今度は、 temperature_3.txtというファイルを使います。 このデータでは、 33行目から42行目まで、Site01 の値が -999 になっています。これは、その日のデータが欠測であることを 示しています。この数値をそのまま使って平均を計算しては大変なことになります。 ふつう、R ではデータが欠けているところは NA という値をいれて扱います。 read.table でデータを読む時も、na.strings というオプションで「この値が入っていたら NA だと解釈せよ」 という指定ができます。
d <- read.table('temperature_3.txt', header = TRUE, na.string = '-999')
このデータを対象に、サイトごとの平均気温を計算するとどうなるでしょうか。
d <- read.table('temperature_3.txt', header = TRUE, na.string = '-999')
site.means <- apply(d, 2, mean)
を実行してから site.means を見ると、
> site.means
Site01 Site02 Site03
NA 11.95644 17.96466
のように、Site01 の年間平均は NA になっています。これは、 mean という関数は与えられた データのなかにひとつでも NA があると、答えも NA を返すという仕様になっているからです。 たしかにこれは安全なのですが、ごく一部の欠測のために残りのデータを使うのを諦めるのは もったいないことです。
NA を含むデータを受け取ると NA を返す関数では、NA があったらまずそれを 除いてから、残りのデータを処理するというオプションが用意されていることがあります。 mean の場合、na.rm という引数に TRUE を設定すると、NA は削除(remove)してから 平均が計算されます。 apply で使う関数にこのようなオプションを設定するには、関数のあとにオプション指定を書きます。
d <- read.table('temperature_3.txt', header = TRUE, na.string = '-999')
site.means <- apply(d, 2, mean, na.rm = TRUE)
上のコードを実行してから site.means を見ると、
> site.means Site01 Site02 Site03 6.253521 11.956438 17.964658
と、Site01 でも平均が計算されています。
apply に渡す関数は、あらかじめ用意されているものではなく、自分で定義したものでもかまいません。 関数の定義のしかたは、 第1章で簡単に説明しました。 (さらに詳しくは R-tips (31. 関数の定義) などを見てください。
ためしに、数値のベクトルを受け取って、最大値と最小値の差を返す関数を作って、これを apply に渡してみます。
d <- read.table('temperature_2.txt', header = TRUE)
range.width <- function(x) {return (max(x) - min(x))} # 最大と最少の差を計算する関数を定義する
annual.dif <- apply(d, 2, range.width) # 3地点それぞれでの、年間の最暑日、最寒日の日平均気温の差
上のコードを実行したあと、annual.dif の中身を見ると、以下のようにそれぞれのサイトでの年間の温度差が 入っています。
> annual.dif Site01 Site02 Site03 36.6 25.7 17.3 ...
なお、関数は上のように名前を付けてから apply に渡してもよいし、簡単なものなら いちいち名前をつけず、 apply 中にじかに書いてしまうこともできます。
d <- read.table('temperature_2.txt', header = TRUE)
annual.dif <- apply(d, 2, function(x) {return (max(x) - min(x))}) # 毎日の、年間の最暑日、最寒日の日平均気温の差
apply に限らず以下で説明する他の apply 系関数でも、 同様に自作関数を渡すことができます。
applyの2番めの引数として、ひとつの数値だけではなく、複数の数値が並んだベクトルを渡すこともできます。 データが二次元の場合、2番めの引数に c(1, 2) を渡すと、行と列の組み合わせで決まるデータ、 すなわち行列の一つ一つの要素を関数に渡します。
apply に渡せるデータは、二次元に限りません。R の配列は多次元の構造を持てるのですが、 apply は3次元以上の配列も処理できます。N 次元の配列を渡した場合、2番めの引数は 1 か 2 かに 限らず、N まで設定できます。 その場合の動作は R-Tips の 配列のページ などで調べてください。
種類A の生き物の計測値たくさんと、種類Bの生き物の計測値がたくさん、というように 複数のグループのデータがまとまっているとします。 このような場合、計測データと、グループの種別の情報とを渡すと、 グループごとにデータをまとめて関数に渡して処理してくれるのがtapply です。 ちょっと分かりにくいのですが、下の概念図で感じを掴んでから説明を読んでください。 図中の T がグループを識別する情報、X が処理したいデータ、F がデータを処理する関数です。
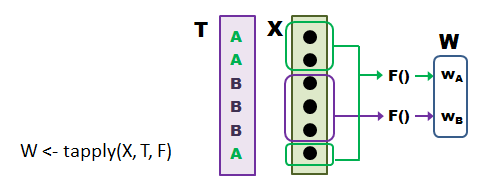
たくさんの生き物の体長と、その生き物の種類を調べた仮想データを使って、さっそく試してみます。 データファイルは len__sp.txtです。 内容は、体長(len)と種(s)のデータが50個体分並んだものです。
len sp 58.2 Sp2 54.7 Sp1 47.4 Sp1 38.6 Sp1 46.5 Sp2 51.2 Sp2 47.8 Sp2 ...
長さの平均を種ごとに求めるには、これをデータフレームに読み込み、sp が Sp1 のデータだけ抜き出したり、 Sp2 のデータだけ抜き出したりしてから、平均を計算するという方法がありますが、 tapply を利用すると、データの抜き出しなどの作業なしで、種ごとの平均を計算できます。 tapply に渡す最初の引数は処理したいデータ、2番目は種別の情報、3番目はデータを渡す関数(この場合は mean)です。
d <- read.table('len_sp.txt', header = TRUE)
len.means <- tapply (d$len, d$sp, mean)
tapply が返すのは一次元の配列です。 分類に使ったデータの値(この例だと Sp1 と Sp2)が、配列の各要素の名前になっています。 以下で確認してください。
> len.means
Sp1 Sp2
50.23182 48.89643
> names(len.means)
[1] "Sp1" "Sp2"
> len.means[1]
Sp1
50.23182
> len.means['Sp1']
Sp1
50.23182
tapply に渡す最初の引数はベクトルです。 2番めの、分類に使うデータ(たとえば種名)は、正確にはリストを渡すことになっています。 上の例では d$sp という要素数 50のベクトルを渡していますが、 tapplyはこれをひとつのベクトルを要素として持つリストが渡されたものと解釈して 処理してくれます。 ここを自動変換に任せずにていねいに書くなら、
d <- read.table('len_sp.txt', header = TRUE)
len.means <- tapply (d$len, list(d$sp), mean)
となります。
このリストの要素はひとつとは限らず、2つ以上渡すことができます。 というよりも、いくつも束ねて渡すために、リストに詰め込むという仕様になっているのだと思います。 ここに複数のベクトルを束ねて渡すと、それらの組み合わせごとにデータをまとめて関数に渡します。 と言っても分かりにくいので、実例で見てみます。 データファイルは len__sp_loc.txtです。 さきほどのlen__sp.txt に、採集地(A と B)の情報が入った列 location を加えたものです。
len sp location 58.2 Sp2 A 54.7 Sp1 B 47.4 Sp1 A 38.6 Sp1 B 46.5 Sp2 A 51.2 Sp2 B 47.8 Sp2 A 71.7 Sp2 B ...
二番目の引数に、 d$sp というベクトルと、d$location というベクトルを要素として持つ 長さ 2 のリストを指定すると、結果は以下のようになります。
d <- read.table('len_sp_loc.txt', header = TRUE)
len.means2 <- tapply (d$len, list(d$sp, d$location), mean)
> len.means2
A B
Sp1 51.38000 49.27500
Sp2 48.86667 48.93077
2つの分類用データを束ねて渡すと、それらの組み合わせごと(種が Sp1 で場所が A の場合、種が Sp1 で場所が B の場合…) に解析対象データをまとめて、関数(ここでは mean) に渡して計算して、その結果を二次元の配列にしまって返してくれます。
apply は、行列やデータフレームのように二次元の表にできるようなデータを対象に、 行方向、列方向にまとめてデータ処理をするのに使いました。 一次元にデータが並んだベクトルないしはリストを渡して、各要素ごとに関数に渡して処理するには、 lapply や sapply を使います。以下が概念図です。 X はデータ、 F はデータを処理する関数です。
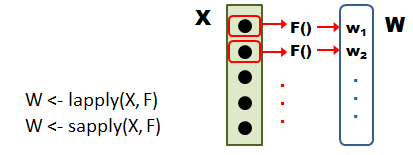
lapply はリストを返し、sapply は(可能なら)リストではなく ベクトルや行列を返す点が違います。 関数が単純な数値を返すものなら、sapply が便利です。 また、関数がリストや複雑なオブジェクトを返すものなら、 それらをそのままリストに並べて返してくれるlapply がよいでしょう。 リストには何でも並べられるけれど、ベクトルや行列は単純な数値、文字列、論理値しか 持てないことを思い出してください。
以下は、受け取った数の二乗を返すという単純な関数を sapply に渡しています。
v <- 1:10 # 1から10の数値が並んだベクトル
x.sqr <- sapply(v, function(x) {return (x^2)}) # 各要素の二乗を計算
x.sqr のなかを見てみます。
> x.sqr [1] 1 4 9 16 25 36 49 64 81 100
このように、x.sqr は10個の計算結果が並んだベクトルです。
sapply ではなく lapply を使ったらどうなるかも確認してみましょう。
v <- 1:10 # 1から10の数値が並んだベクトル
x.sqr2 <- lapply(v, function(x) {return (x^2)}) # 各要素の二乗を計算
x.sqr2 のなかを見てみます。
> x.sqr2 [[1]] [1] 1 [[2]] [1] 4 ... [[10]] [1] 100
確かに 10個の要素を持つリストができています。
以下は、 lapply で得た「リストのリスト」から、sapply を使って要素を取り出す例です。
v <- 1:10 # 1から10の数値が並んだベクトル
sqr.cub <- function(x) { # 受け取った値の二乗と三乗を計算し、リストに束ねて返す。
x1 <- x^2
x2 <- x^3
x.list <- list(x1, x2) # 二乗と三乗をリストに束ねる。
names(x.list) <- c('sqr', 'cub') # リストの各要素に名前をつける('sqr'と 'cub')
return(x.list) # リストを返す。
}
y <- lapply(v, sqr.cub) # 各要素の二乗と三乗を計算する。
このプログラムを実行して作った y は、10個の要素が並んだリストです。 個々の要素はリストで、それぞれ2個の数値(受け取った値の二乗と三乗)をデータとして持っています。 そして、2個の数値には'sqr'と 'cub'という名前がついています。
まずは、リスト中の要素(ここでは2個の数値を含むリスト)をひとつ表示します。 3番めの要素を表示してみましょう。 y[[3]]と、二重のカギカッコを使います。 (カギカッコを一重にして y[3] と書くと、y の3番目の要素のみを含む長さが 1 のリストを意味します。 この区別に注意してください。)
> y[[3]] $sqr [1] 9 $cub [1] 27
これは、とりだした3番めのリストの、sqr という名前の要素は 9 というひとつの数値、 cub という名前の要素は 27 というひとつの数値、ということです。
次に、3番めのリストから、三乗の値のみを取り出します。
> y[[3]][['cub']] # 3番目のリストの、'cub' という名前の要素の値 [1] 27
ここでも、二重カギカッコで要素そのものを指示していることがポイントです。
最後に、y に含まれる 10個のリストから、それぞれに含まれる「三乗の値」('cub') をまとめて取り出してみましょう。 以下は、ほとんどおまじないに見えるかもしれません。 演算子を関数として使うという、不思議な技です。
cubs <- sapply(y, "[[", "cub")
上の一行を説明します。 sapply を使って、y という「リストのリスト」の各要素(すなわちリスト)を、ひとつづつ 関数 "[[" に渡します。 二重カギカッコ "[[ ]]" は、リストから指定要素を取り出す演算子で、これも関数として扱えるのです (どういうわけか、関数名としては [[ ]] ではなく左カッコ [[ のみを書きます)。 apply と同様に、sapply や lapply でも 関数に渡したい他の引数を指定できます。 この引数として、二重カギカッコ演算子に渡したい要素名、すなわち 'cub'を指定しています。 その結果、y という「リストのリスト」の各要素(すなわちリスト)から、'cub'という名前の 要素を取り出し、まとめてベクトルとして返す(lapply ではなく sapply だから)、という 作業が行われます。
sapply が返した値をしまった cubs は、 10個の「三乗の値」からなるベクトルです。
> cubs [1] 1 8 27 64 125 216 343 512 729 1000
リスト中の要素は、名前ではなく、何番目かという数値で指定することもできます。 以下のように試してみましょう。 各リストの1番めの要素は二乗、2番めの要素は三乗です。
> sapply(y, "[[", 1) [1] 1 4 9 16 25 36 49 64 81 100 > sapply(y, "[[", 2) [1] 1 8 27 64 125 216 343 512 729 1000 >
理屈は少々込み入っていますが、「たくさんのリストから、指定する要素を一括して取り出したい」という場合に 役立ちます。
あともう少し。こんどは、たくさんのベクトルが並んだリストから、各ベクトルの要素を取り出してみます。
使うデータは dates.txt です。11個の yyyy-mm-dd という形のデータが入っています(私の研究室の セミナーの予定日です)。 これを読み込んでから、まとめて年、月、日に分割します。 文字列の分割には strsplitという関数を使います。 この関数は、「ひとつの文字列を分割したものが並んだベクトル」が、渡した文字列の数だけ並んだリストを返します。 このリストから、sapplyで年、月、日をまとめて取り出してみます。
d <- read.table('dates.txt') # データフレームに読み込む。
dates <- strsplit(as.character(d[[1]]), "-") # 文字列は"因子型"になるので、文字列型に変換してから渡す。
years <- sapply(dates, "[", 1) # strsplit が返した「リストのリスト」中の、各リストの1番めの要素を並べたベクトル
months <- sapply(dates, "[", 2) # 各リストの2番めの要素を並べたベクトル
days <- sapply(dates, "[", 3) # 各リストの3番めの要素を並べたベクトル
years, months, days は、それぞれ年、月、日のデータが並んだベクトルです。 文字列を分割した結果なので、これらも文字列です。数値として使いたければ、as.numeric で 数値に変換します。
「リストのリスト」からデータを取り出す場合と違って、今度は「ベクトルのリスト」なので、各ベクトルの要素を取り出す には、二重カギカッコではなく、sapply(dates, "[", 1) のように一重カギカッコを使っています。
strsplit の2つ目の引数は、文字列を分割する切れ目を示す文字です。 この例では "-" で区切っています。 yyyy/mm/dd という形式なら、"/" とすればよさそうですが、"/" は特別な意味を持ってしまうので、"/" という文字そのものを意味する、"\\/" を渡します。ここらへんをきちんと理解するには、正規表現というものと、 その R での扱いかたの勉強が必要です。必要があれば調べてみてください。
最後は mapply です。これは、変数 X と 変数 Y (あるいはもっと)を関数に渡して何かの計算をしたい、 ただし X と Y はどちらもたくさんのデータの塊で、1番めの要素同士で計算、2番めの要素同士で計算、… ということを一気にやりたい、というときに使います。 まずは概念図です。 F はデータを処理する関数、X と Y はデータです。
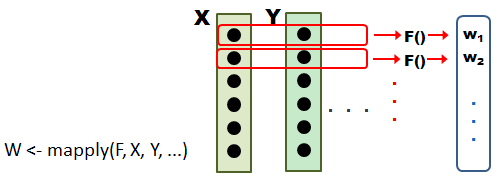
X も Y も数値が並んだ同じ長さのベクトルで、要素同士の足し算をしたいなら、W <- X + Y と書けば計算できますが、 こういう便利なことをしてくれない関数で計算する場合は、mapply の出番です。
以下は、わざとらしい例です。ベクトル同士の足し算は、 A + B でできてしまうのですが、説明のために 2つの変数を受け取って和を返す関数を定義して使っています。
a <- 1:10
b <- 11:20
sum.xy <- mapply(function(x, y) {return (x + y)}, a, b)
これで、 sum.xy の最初の要素は a の最初の要素と b の最初の要素の和、2番めの要素は… という計算が できます。
> sum.xy [1] 12 14 16 18 20 22 24 26 28 30
これまでの apply 系関数とちがって、最初の引数が関数であることに注意してください。 処理してほしいデータのまとまり (上の例では a と b)は2個に限らず何個渡してもよいので、たとえば apply のように最初にデータを渡すように すると、どこまでがデータでどれが関数だか分からなくなってしまいます。
なお、データはベクトルではなくリストであっても同様処理されます。
> mapply(sum, list(1, 10, 1), list(11, 20, 30)) [1] 12 30 31
最後に、私の自作の、緯度・経度とメッシュコードの変換ライブラリ (紹介ページと R版のコード)を使って、 緯度と経度を関数に渡し、その地点を含むメッシュのコードを返すプログラムを紹介します。 メッシュコードとは、日本全国を緯度・経度で格子状に区切り、その各区画に規則的に当たれられた番号です。 格子の細かさにより、一番粗い一次メッシュのほか、より細かい二次メッシュ、三次メッシュが定義されています。 一次メッシュの各区画は 20万分の1の地図に、二次メッシュは2万5千分の1の地図に相当します。
以下のプログラムを実行するには、 mesh_lib.Rをダウンロードして、 作業を行うディレクトリに入れておいてください。
source('mesh_lib.R') # ライブラリの読み込み
lat <- c(33, 35, 37, 40) # 緯度のデータ
long <- c(132, 139, 140, 141) # 経度のデータ
mesh.code3 <- mapply(latlong_to_meshcode, lat, long) # デフォルトでは三次メッシュ
mesh.code2 <- mapply(latlong_to_meshcode, lat, long, MoreArgs = list(order = 2)) # 二次メッシュ
mesh.code1 <- mapply(latlong_to_meshcode, lat, long, MoreArgs = list(order = 1)) # 一次メッシュ
緯度のベクトルと、経度のベクトルから一つづつデータを取り出し、メッシュコードに変換する関数 latlong_to_meshcode に渡して処理してます。 計算の結果は以下の通りです。
> mesh.code1 [1] 4932 5239 5540 6041 > mesh.code2 [1] 493240 523940 554040 604100 > mesh.code3 [1] 49324000 52394000 55404000 60410000
何次メッシュを計算するかは、order という引数で指定します。mapply では、計算対象のデータ以外で 関数に渡したい引数は、 上の例のように MoreArgs = list(...) という形で指定します。 list(order = 1) は、値が1で、名前が order という要素をひとつ持つリストを意味します。 指定したいオプションがいろいろあるなら、 MoreArgs = list(op1 = 1, op2 = TRUE, ...) というように、カンマで区切って並べて書きます。
このページで説明したapply系関数を表にまとめました。
| apply系関数 | 渡すデータ | 機能 |
|---|---|---|
| apply | 2次元(以上)の行列構造のデータ(データフレームなど)と、 データ処理関数 | オプション指定により、データを行ごと(1) / 列ごと(2) にまとめてデータ処理関数に渡す |
| tapply | データのベクトル、各データの所属グループを示す因子のベクトル(or リスト)と、 データ処理関数 | 所属グループごとにデータを束ねてデータ処理関数に渡す。 |
| lapply | データのベクトルないしはリストと、データ処理関数 | データのひとつひとつの要素をデータ処理関数に渡す。 処理結果のリストを返す。 |
| sapply | データのベクトルないしはリストと、データ処理関数 | データのひとつひとつの要素をデータ処理関数に渡す。 処理結果は、可能ならベクトルないしは行列ないしは配列のかたちで返す。 |
| mapply | データ処理関数と、複数のベクトル(ないしはリスト) | 全ベクトルの N 番目の要素をまとめてデータ処理関数に渡す。 |
※ apply 系関数が返す値の型は、データ処理関数が返す値の型に依存するので、注意して確認すること (ベクトルか、行列か、配列か、リスト(含むリストのリスト)か)
私はこれまで、いつくもある apply 系関数の全体像が把握できていませんでしたし、 そもそも、それぞれの関数の使いかたも、おぼつかないものでした。 このページを書くことで、ずいぶん頭の整理ができました。 とはいえ、まだ理解が十分ではないところも多々あり、そのためにまちがったことも書いているかもしれません。 お気づきの点はぜひお知らせください。